

Decision Tree
决策树算法属于监督学习,决策树是一个类似一流程图的树型结构,每个内部结点表示在一个属性上的测试,每个分支代表一个属性输出,每个树叶结点代表类或者类分布,树的最顶层是根结点。

- 每个结点进行一个属性的检测
- 每个分支代表属性的一个可能取值,分支到不同结点
- 每个结点有关于类别的分布
构造决策树的算法
熵(entropy)
对于不确定的事件,通过信息量來度量,越不确定一件事,需要的信息量越大
熵计算公式如下:
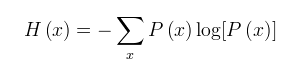
决策树归纳算法(ID3)
构造决策树时怎么选择结点,用于选择属性判断结点。
通过变量值信息获取量(Information Gain)來判断,一个属性的信息获取量计算:
Gain(A) = Info(D) - Info_A(D)
即没有A时的信息量减去加上A之后的信息量,差值作为判断标准(D是数据集,A是属性),步骤如下:
1 计算事件总的熵
2 针对每一个属性进行划分,然后计算划分的每一个熵
3 利用信息量获取计算公式计算出每个属性的信息获取量
4 选择最大的信息量的结点
5 剩下的节点进行重复计算

